Internals and architecture
SQream DB internals
Here is a high level architecture diagram of SQream DB’s internals.
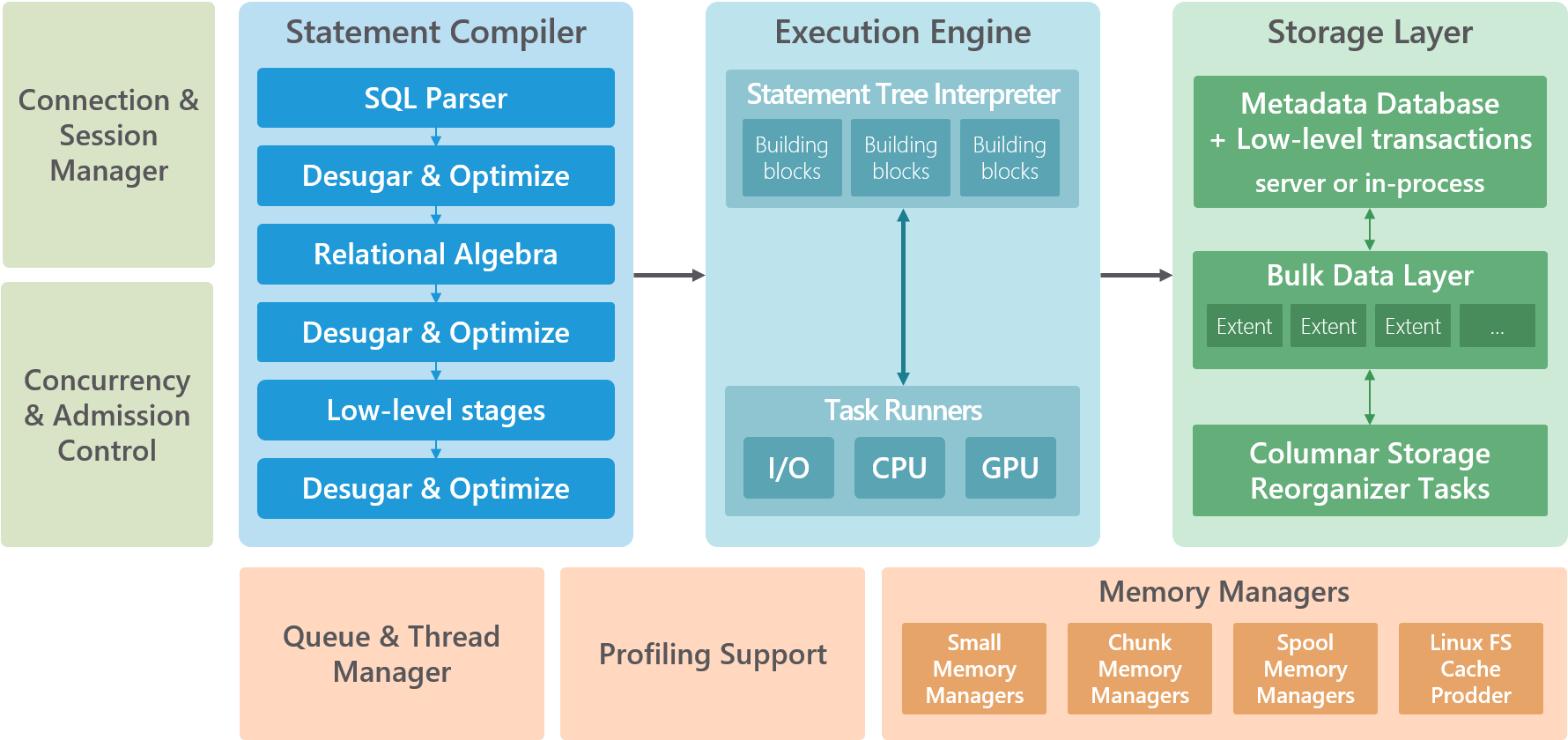
Statement compiler
The statement compiler is written in Haskell. This takes SQL text and produces an optimised statement plan.
Concurrency and concurrency control
The execution engine in SQream DB is built around thread workers with message passing. It uses threads to overlap different kinds of operations (including IO and GPU operations with CPU operations), and to accelerate CPU intensive operations.
Transactions
SQream DB has serializable transactions, with these features:
Serializable, with any kind of statement
Run multiple SELECT queries concurrently with anything
Run multiple inserts to the same table at the same time
Cannot run multiple statements in a single transaction
Other operations such as DELETE, TRUNCATE, and DDL use coarse-grained exclusive locking.
Storage
The storage is split into the metadata layer and an append-only/ garbage collected bulk data layer.
Metadata layer
The metadata layer uses RocksDB, and uses RocksDB’s snapshot and write atomic features as part of the transaction system.
The metadata layer, together with the append-only bulk data layer help ensure consistency.
Bulk data layer
The bulk data layer is comprised of extents, which are optimised for IO performance as much as possible. Inside the extents, are chunks, which are optimised for processing in the CPU and GPU. Compression is used in the extents and chunks.
When you run small inserts, you will get less optimised chunks and extents, but the system is designed to both be able to still run efficiently on this, and to be able to reorganise them transactionally in the background, without blocking DML operations. By writing small chunks in small inserts, then reorganising later, it supports both fast medium sized insert transactions and fast querying.
Building blocks
The heavy lifting in SQream DB is done by single purpose C++/CUDA building blocks.
These are purposely designed to not be smart - they have to be instructed exactly what to do.
Most of the intelligence in piecing things together is in the statement compiler.
Columnar
Like many other analytical database management systems, SQream DB uses a column store for tables.
Column stores offer better I/O and performance with analytic workloads. Columns also compress much better, and lend themselves well to bulk data.
GPU usage
SQream DB uses GPUs for accelerating database operations. This acceleration brings additional benefit to columnar data processing.
SQream DB’s GPU acceleration is integral to database operations. It is not an additional feature, but rather core to most data operations, e.g. GROUP BY, scalar functions, JOIN, ORDER BY, and more.
Using a GPU is an extended form of SIMD (Single-instruction, multiple data) intended for high throughput operations. When GPU acceleraiton is used, SQream DB uses special building blocks to take advantage of the high degree of parallelism of the GPU. This means that GPU operations use a single instruction that runs on multiple values.