Python modules (Python Scalar Functions)
SQream’s Python Module enables users to integrate custom Python code and functions directly. This allows for advanced data manipulation and custom machine learning operations, all accelerated by GPU.
Syntax
CREATE OR REPLACE MODULE module_name
OPTIONS
( path = '...'
, entry_points =
[
[ name = 'handler_name'
, param_types = [sql_data_type, ...]
, return_type = sql_data_type
, gpu_acceleration = {TRUE|FALSE}
]
, [ name = 'handler_name2'
, param_types = [sql_data_type, ...]
, return_type = sql_data_type
]
...]
);
module_name ::= identifier
gpu_acceleration ::= Boolean
path ::= Valid path within module directory
sql_data_type ::= INT | BIGINT | SMALLINT | DECIMAL precision scale| NUMERIC precision scale | FLOAT | REAL | DOUBLE | TEXT | DATE | DATETIME | BOOLEAN
handler_name ::= name of function within the python script file
Examples
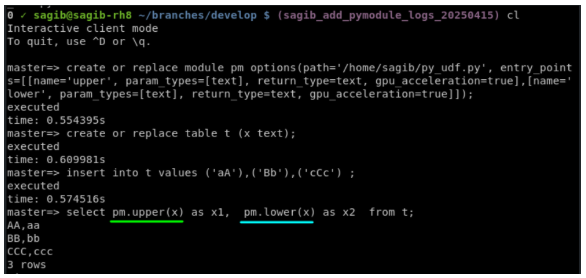
Example 1 - Python module creation in Sqream:
CREATE OR REPLACE MODULE my_module OPTIONS (
path = '/home/sagib/py_udf.py',
entry_points = [
[ name = 'upper' ,
param_types = [text] ,
return_type = text ,
gpu_acceleration = TRUE ],
[ name = 'lower' ,
param_types = [text] ,
return_type = text ,
gpu_acceleration = FALSE]
]);
Example 2 - Python module + Sqream execution: Create a Python file ‘/tmp/myArithmetic.py’:
import pandas as pd
def myAdd(df):
df['sum'] = df.iloc[:,0] + df.iloc[:, 1]
return df['sum']
def mysubtract(df):
df['sub'] = df.iloc[:,0] - df.iloc[:, 1]
return df['sub']
In SQream - Create Python module:
CREATE OR REPLACE MODULE arith_module OPTIONS
( path = '/tmp/myArithmetic.py'
, entry_points =
[
[ NAME = 'myAdd',
PARAM_TYPES =[INT, INT],
RETURN_TYPE = INT,
GPU_ACCELERATION = TRUE ]
, [ NAME = 'mySub',
PARAM_TYPES =[INT, INT],
RETURN_TYPE = INT,
GPU_ACCELERATION = FALSE ]
]
);
Execute python module:
create or replace table t (x int, y int);
insert into t values (1,1);
insert into t values (2,2);
insert into t values (3,3);
insert into t values (4,2);
select arith_module.myAdd(x,y) from t;
--yields: 2, 4, 6, 6
select arith_module.mySub(x,y) from t;
--yields: 0, 0, 0, 2
Configurations:
Sqream configuration: In this version, Python module service is per Sqream worker only. It is required to set configuration change regarding communication details in Sqream config:
Config file |
Flag name |
Flag type |
Default value |
|---|---|---|---|
Sqream config (not legacy) |
pythonModulesGrpcPort |
Worker |
50051 |
Sqream config (not legacy) |
grpcGpuAllocatorPort |
Worker |
50052 |
Python module configuration: Service’s configuration is located in etc/python_service_config.json:
{
"port": 50051,
"gpu_alloc_port": 50052
}
Note
Worker flag means it can’t be changed while the worker is up, the change will occur only after Sqream workers restart. Python module flags must match Sqream worker’s flags mentioned above.
Logs:
Python module service has a log configuration file. Logs can be either shown to screen, and also be exported to file (same as we have in Sqream’s log4cxx log configuration).
File path: etc/python_service_log_properties.
File content:
Configuration file |
Explanation |
|---|---|
|
keys=root |
|
keys=consoleHandler,fileHandler |
|
keys=standardFormatter |
|
level=DEBUG, handlers=consoleHandler,fileHandler |
|
class=StreamHandler, level=INFO, formatter=standardFormatter, args=(sys.stdout,) |
|
class=logging.handlers.RotatingFileHandler, level=DEBUG, formatter=standardFormatter, args=(‘py_module_service.log’, ‘a’, 1048576, 10) |
|
format=%(asctime)s.%(msecs)03d|%(levelname)s|%(message)s, datefmt=%Y-%m-%d %H:%M:%S |
Note
consoleHandler - Responsible for logs that are been shown as console output, handler_consoleHandler: Handler that supplies additional configuration for console output logs. For example:
* Class: Handler category, in this case it will be StreamHandler.
* Level: Required log level (Supported levels: ERROR / WARNING / INFO / DEBUG).
* Formatter: In which format the logs will be shown.
* args: Arguments which are required for the handler class (keep as it is in the example).
fileHandler - Responsible for logs that are been shown as console output, handler_fileHandler: Handler that supplies additional configuration for log files exportation:
* Class: Handler category, in this case it will be RotatingFileHandler.
* Level: Required log level (Supported levels: ERROR / WARNING / INFO / DEBUG).
* Formatter: In which format the logs will be shown.
* args: Arguments which are required for the handler class (keep as it is in the example). Based on the supplied example:
'py_module_service.log'- The location + file name of generated log file.
'a'- Means appending on the same file.
1048576- Max file size in bytes.
10- Keeping up to 10 log files, the rest will be deleted.
formatter_standardFormatter: Used for declaring formats for different uses:
* format=%(asctime)s.%(msecs)03d|%(levelname)s|%(message)s - The log file that will be shown / exported.
* datefmt=%Y-%m-%d %H:%M:%S - Used for internal usage.
Log format: <datetime>|<log_type>|<connection_id>|<statement_id>|<log_message>
Log output example: Python module logs also contain Connection & Session id information, in order to understand what was Sqream’s executed statement that triggered those logs. Also, Python module’s logs are on Python module execution level. In case of multiple execution on the same statement it is possible to correlate between both sides.
In SQream:
Show node info: (Can see statement’s python execution on node id level):
7,1,PushToNetworkQueue ,3,1,3,2025-04-20 20:08:49,-1,,,,2,0.0012
7,2,Rechunk ,3,1,3,2025-04-20 20:08:49,1,,,,2,0.0002
7,3,GpuToCpu ,3,1,3,2025-04-20 20:08:49,2,,,,2,0.0006
7,4,sqream::PythonModule,3,1,3,2025-04-20 20:08:49,3,,,,2,0.0173
7,5,sqream::PythonModule,3,1,3,2025-04-20 20:08:49,4,,,,2,0.1249
7,6,ReorderInput ,3,1,3,2025-04-20 20:08:49,5,,,,2,0.0001
7,7,GpuDecompress ,3,1,3,2025-04-20 20:08:49,6,,,,2,0.0001
7,8,CpuToGpu ,3,1,3,2025-04-20 20:08:49,7,,,,2,0.0092
7,9,Rechunk ,3,1,3,2025-04-20 20:08:49,8,,,,2,0.0002
7,10,CpuDecompress ,3,1,3,2025-04-20 20:08:49,9,,,,2,0.0001
7,11,ReadTable ,3,1,3,2025-04-20 20:08:49,10,0MB,,master.public.t,2,0.0018
Python module logs:

Note
Logs mentioned in this example can be shown both on console / exported to log file.
module_uid: Python module execution unique identifier - contains:
* Connection ID
* Statement ID
* Node ID (Execution tree identifier from show node info)
How to run Python module service
One-time installation
Download Python module service supplied by Sqream.
Extract gzip package:
tar -xvf <Python_module_package>;Create a virtual environment for service’s required python installations:
python3.11 -m venv my_venv;source my_venv/bin/activateInstall required python3.11 libraries, trigger
requirements.txtinstallation file afterwards (will take few minutes):sudo yum install -y python3.11-devel; pip3.11 install -r requirements.txt
Note
Require Python3.11 as a pre-requisite.
All installations are done on a created virtual environment and won’t impact python installations from outside.
Requirements.txtcontains python libraries which are a must for basic python module service functionality.In case more libraries are required (required by customer’s python functions), those installations must be done in the virtual environment and manually by the customer / added to
requirements.txtfile.
Generate Protobuffers’ required Python module service libraries:
bash make.sh;
After execution - some Python files got generated (for internal usage only:
* py_modules_pb2.py
* py_modules_pb2_grpc.py
* sqream_gpu_alloc_pb2.py
* sqream_gpu_alloc_pb2_grpc.py
Run Python module service:
Activate virtual environment:
source my_venv/bin/activateRun python module service:
python3.11 py_modules.py
Python module service is working when it is listening to its relevant port:

User notes & limitations:
Environmental:
Python version is limited to the SQream prerequisites compiled version, that means the user must align to the recent SQream version, and upgrading a python version, requires upgrading SQream package.
Python code would run with default Linux privileges therefore could be potentially dangerous and need to be handled with caution.
As mentioned above - In this version there can be a python module service per worker.
Python module syntax:
Param_typesfield may be empty - for example a function that returns timestamp.By default,
param_typesandreturn_typeare nullable, mirroring the behavior of DDL statements. To enforce non-null input or output parameters, users must explicitly specify this requirement.
Python module execution notes:
Python module service in this version supports only functions that return scalar value (a single value). In Python perspective, a function that returns a dataframe that contains 1 column only. In the next version Python module will be able to return DF with multiple columns (table functions).
Python module’s main purpose is for batch processing, which means, python functions will occur chunk by chunk separately. For example, for ‘max’ function (which is aggregational function), instead of getting one maximum value from all chunks, we will get the maximum per chunk.
Chunk processing is limited to default chunk size (E.g. 1M), and cannot be customized when invoked.
In addition to memory constraints, we have no control over RAM memory consumed within the Python module which may cause runtime errors of OOM.
Python functions that would print to stdout would be visible only where Python module’s process is running.
Error handling should work properly, Python errors would get raised in Sqream as runtime errors.
Python module’s file path - Currently local paths are supported only.
Unsupported functionalities:
Nested Python module calls are not supported, functions that call other Python module functions, etc.
Array data type - isn’t supported in this version.
Currently will be supported only on current DB.